
Lecture 17 - Syntax Analysis Part 6 and Context-Sensitive Analysis
YACC: parse.y
%{
#include <stdio.h>
#include "attr.h"
int yylex();
void yyerror(char * s);
#include "symtab.h"
%}
%union { tokentype token; }
%token PROG PERIOD PROC VAR ARRAY RANGE OF
%token INT REAL DOUBLE WRITELN THEN ELSE IF
%token BEG END ASG NOT
%token EQ NEQ LT LEQ GEQ GT OR EXOR AND DIV NOT
%token ID CCONST ICONST RCONST
%start proram
%%
program : PROG ID ';' block PERIOD
;
block : BEG ID ASG ICONST END
;
%%
void yyerror(char* s) {
fprintf(stderr, "%s\n", s);
}
int main() {
printf("1\t");
yyparse();
return 1;
}Error Recovery in Shift-Reduce Parsers
The problem: parser encounters an invalid token Goal: Want to parse the rest of the file
Basic idea (panic mode):
- Assume something went wrong while trying to find handle for non terminal A
- Pretend handle for A has been found; pop “handle”, skip over input to find terminal that can follow A
Restarting the parser (panic mode):
- Find a restartable state on the stack (has transition for nonterminal A)
- Move to a consistent place in the input (token that can follow A)
- perform (error) reduction (for nonterminal A)
- print an informative message
Error Recovery in YACC
Yacc’s error mechanism (note: version dependent!)
- Designated token
error - Used in error productions of the form
A -> error 𝛂 - 𝛂 specifies synchronization points
When error is discovered
- pops stack until it finds state where it can shift the
errortoken - resumes parsing to match 𝛂
- special cases:
- 𝛂 = w, where w is string of terminals: skip input until w has been read
- 𝛂 = 𝛆 : skip input until state transition on input token is defined
- special cases:
- Error productions can have actions
cmpdstmt: BEG stmt_list END
stmt_list : stmt
| stmt_list ';' stmt
| error { yyerror("\n***Error: illegal statement\n");}This should:
- Throw out the erroneous statement
- synchronize at ’;’ or ‘end’ (implicit: 𝛂 = 𝛆)
- writes message “***Error: illegal statement” to stderror

Context Sensitive Analysis
There is a level of correctness that is deeper than grammar

To generate code, we need to understand it’s meaning!
Beyond Syntax
These questions are part of context-sensitive analysis
- Answers depend on “values”, i.e., something that needs computation; not parts of speech
- Questions & answers involve non-local information
How can we answer these questions?
- Use formal methods
- Context-sensitive grammars
- Attribute grammars
- Use ad-hoc techniques
- Symbol tables
- Ad-hoc code
In scanning & parsing, formalism won; somewhat different story here.
Telling the story
- The attribute grammar formalism is important
- Succinctly makes many points clear
- Sets the stage for actual, ad-hoc practice (e.g.: yacc/bison)
- The problems with attribute grammars motivate practice
- Non-local computation
- Need for centralized information
We will cover attribute grammars, then move on to ad-hoc ideas (syntax-directed translation schemes)
Attribute Grammars (AGs)
What is an attribute grammar?
- Each symbol in the derivation (instance of a token or non-terminal) may have a value, or attribute
- A context-free grammar augmented with a set of rules
- The rules specify how to compute a value for each attribute
Example grammar

Example
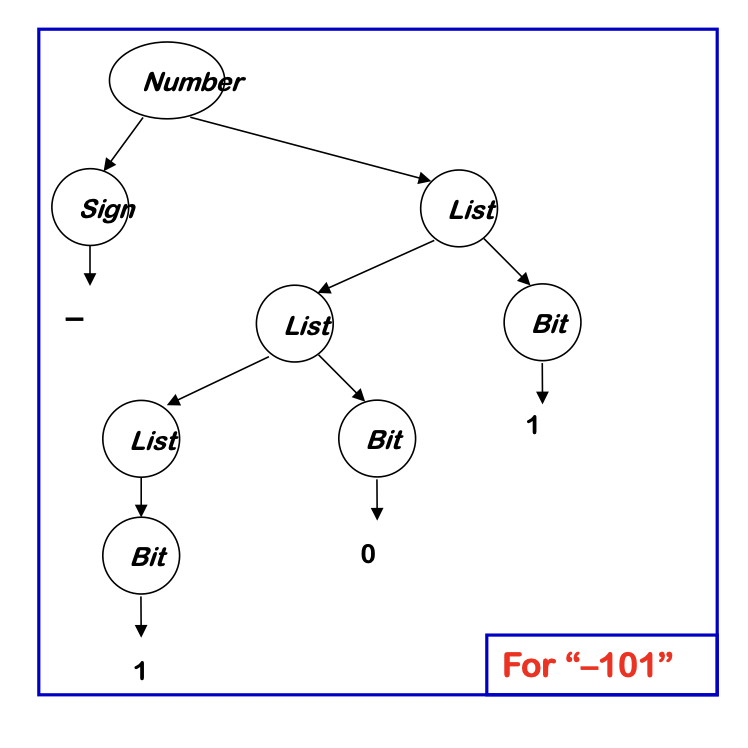
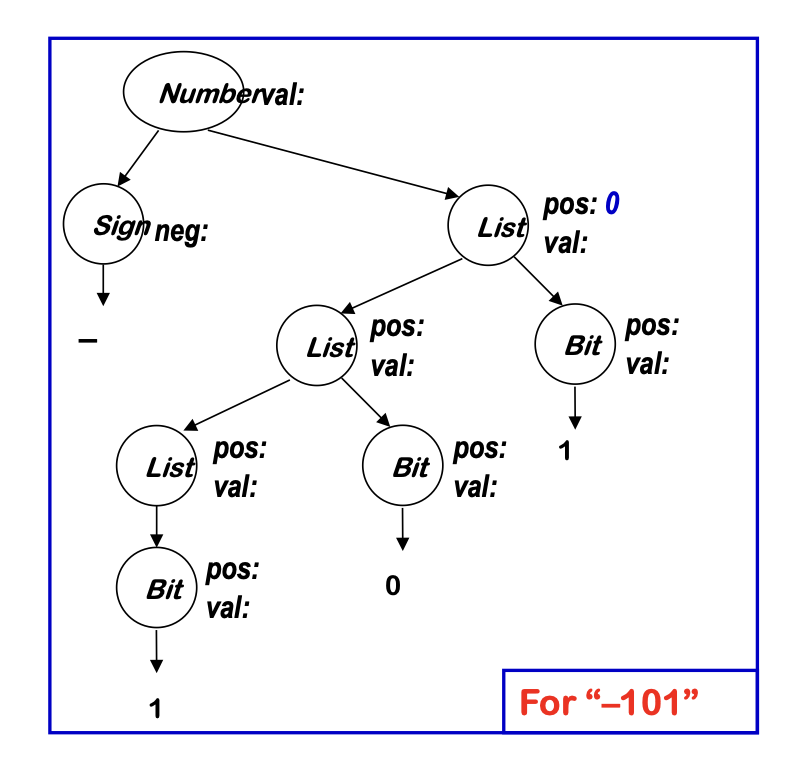
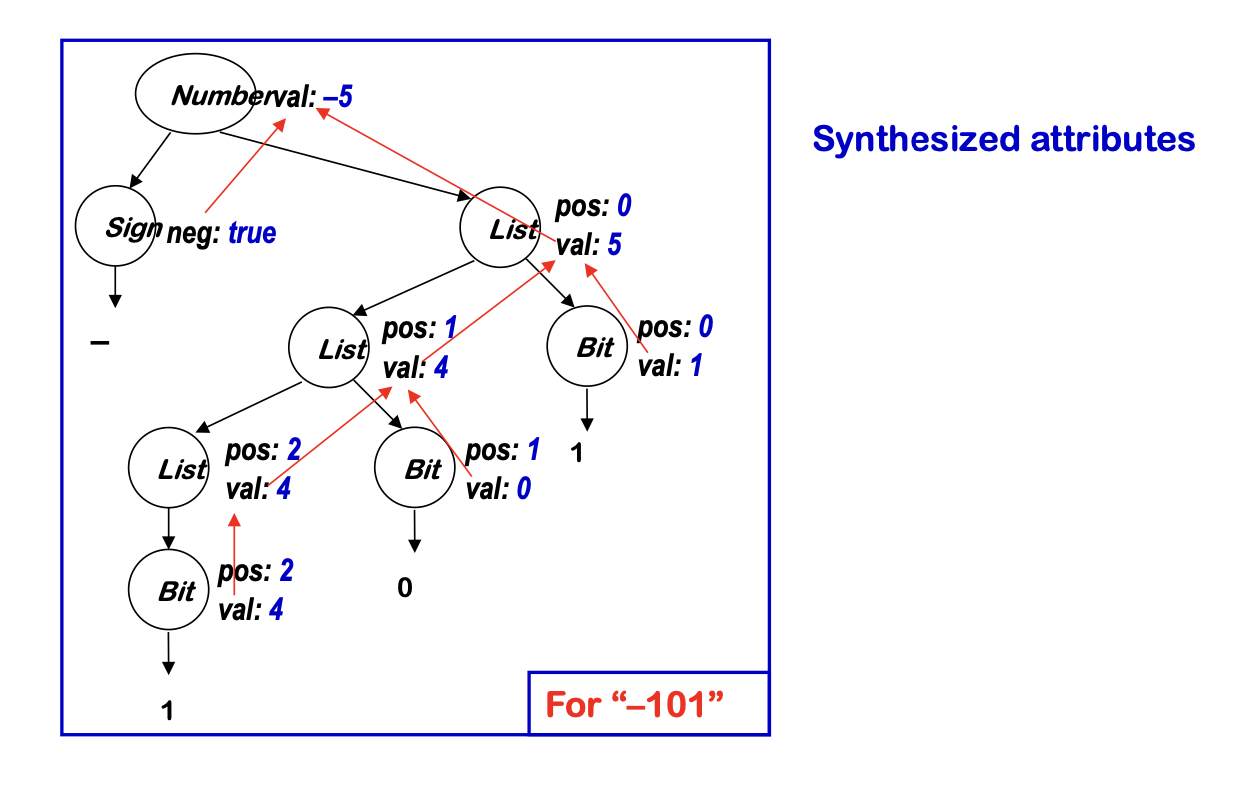
We can add rules to compute the decimal value of a signed binary number
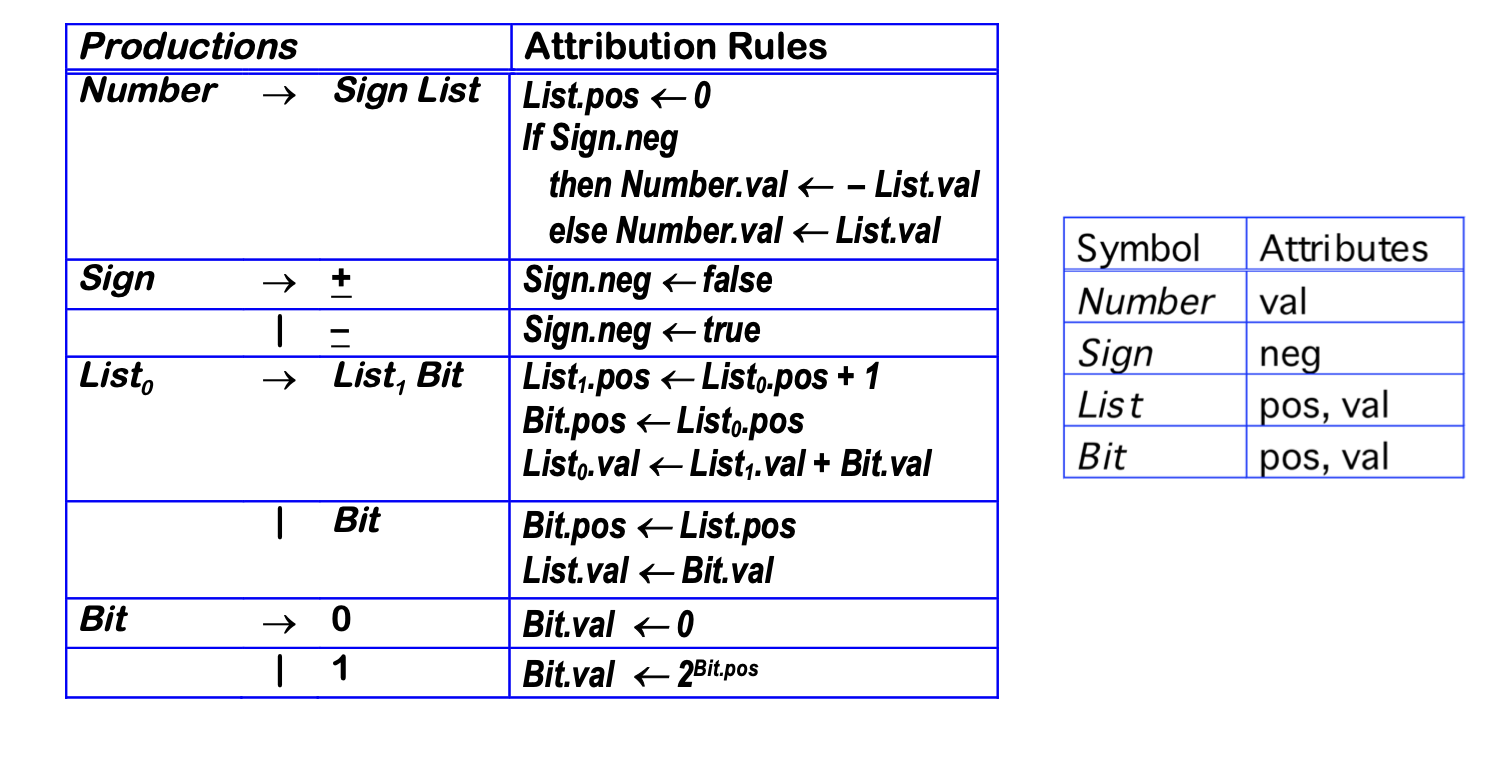
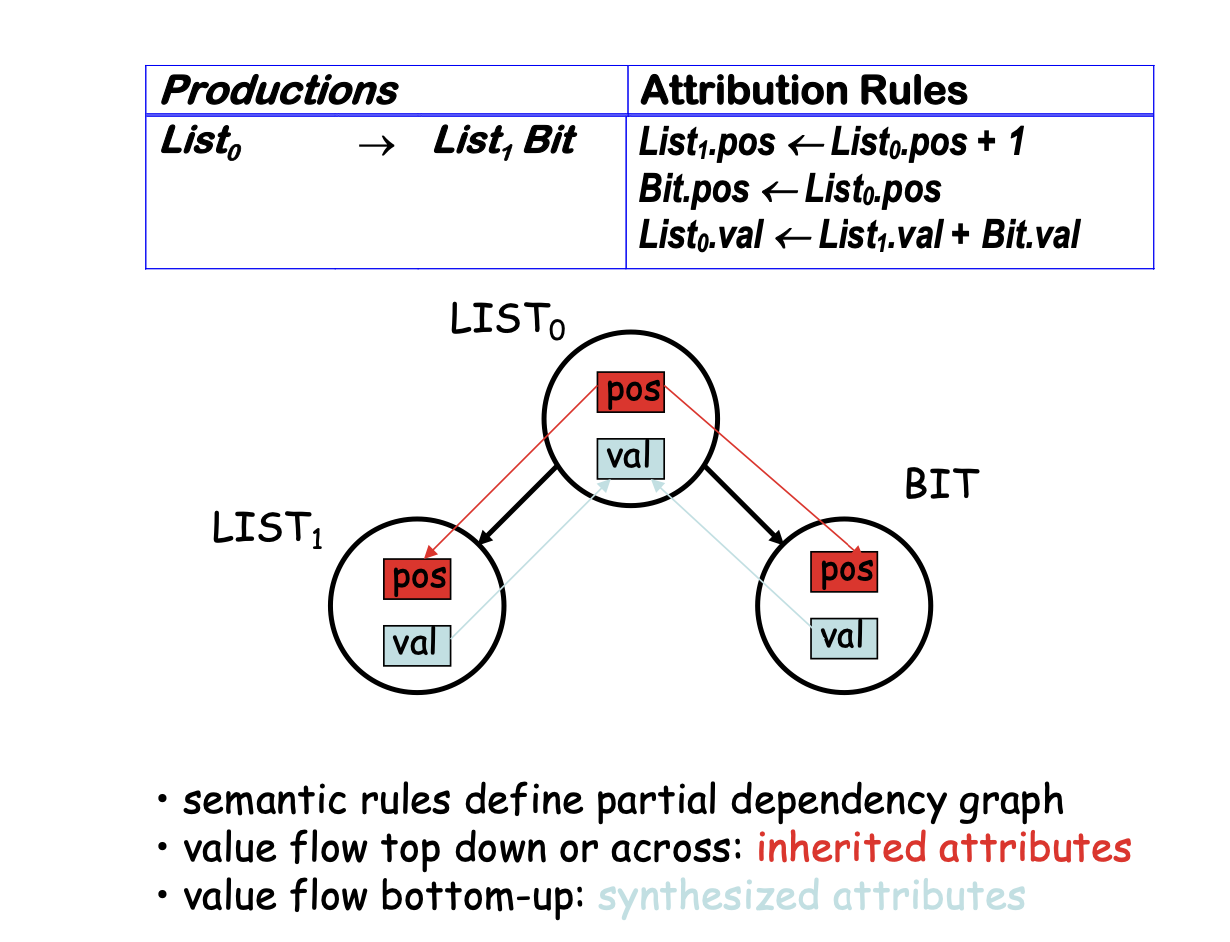
Note: semantic rules associated with production A -> 𝛂 have to specify the values for all
- synthesized attributes for A (root)
- inherited attributes for grammar symbols in 𝛂 (children)
- => rules must specify local value flow!
- Terminals can be associated with values returned by the scanner. These input values are associated with a synthesized attribute
- Starting symbol cannot have inherited attributes
If we peel away the parse tree and just show the computation…
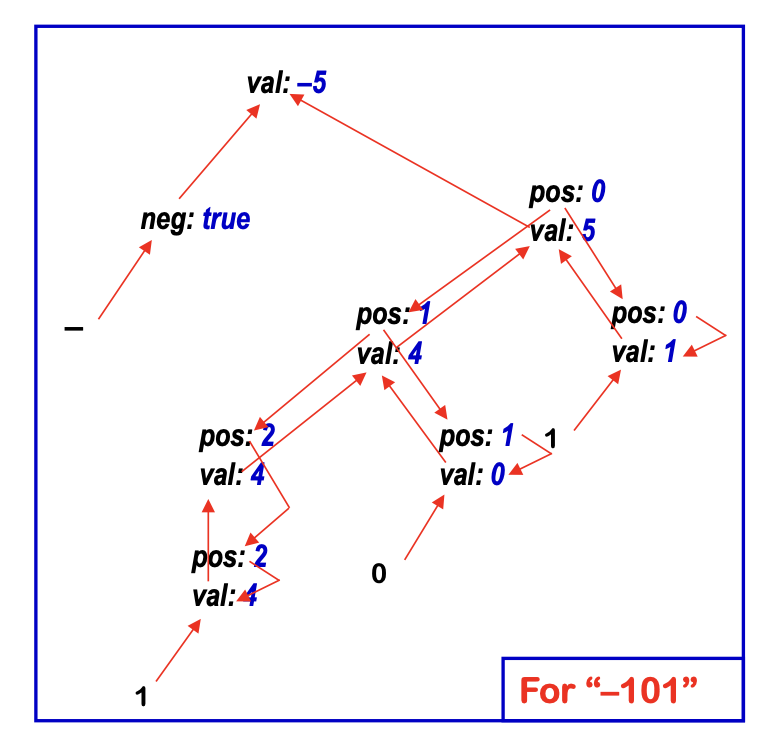
- All that is left is the attribute dependency graph!
- This succinctly represents the flow of values in the problem instance
- The dynamic methods topologically sort this graph, then evaluates edges / nodes in that order
- The rule-based methods try to discover “good” orders by analyzing rules
- The oblivious methods ignore the structure of this graph
NOTE: THIS GRAPH MUST BE ACYCLIC
Using AGs
Attribute grammars can specify context-sensitive actions
-
Take values from syntax
-
Perform computations with values
-
Insert tests, logic, …
-
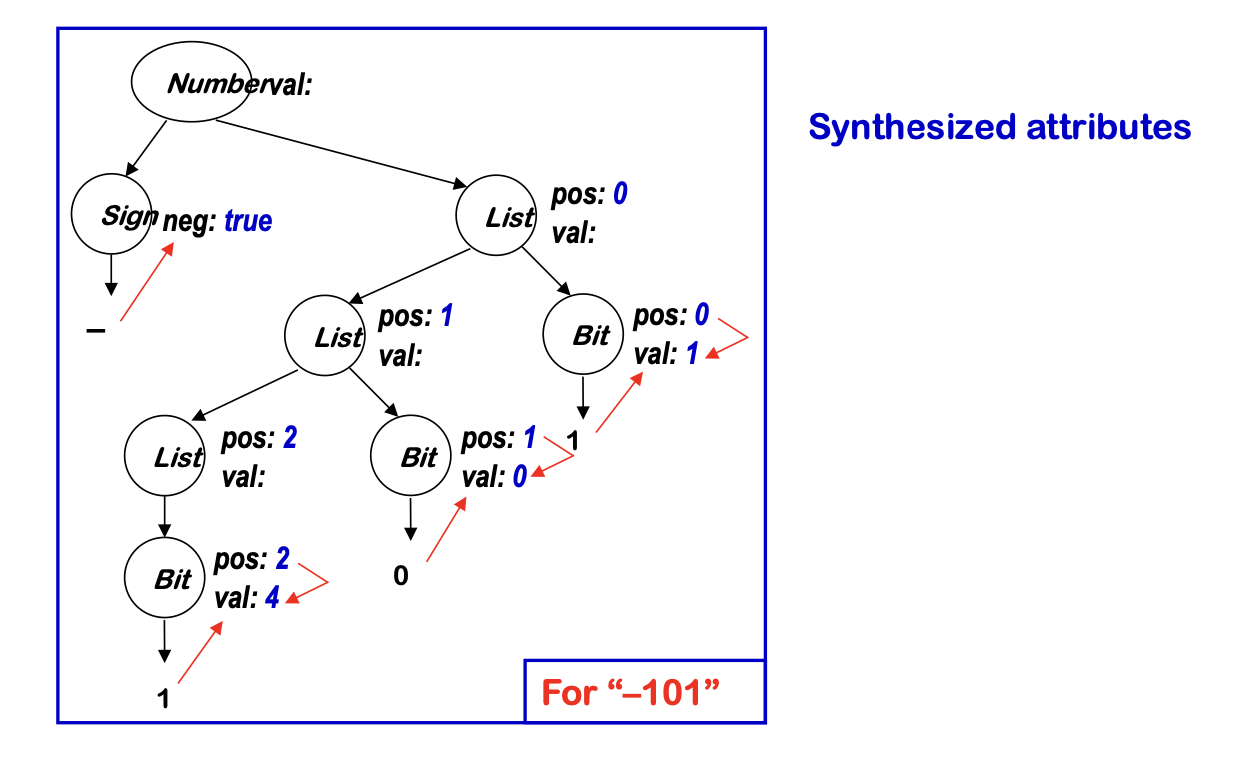
Synthesized Attributes
- Use values from children & from constants
- S-attributed grammars: synthesized attributes only
- Evaluate in a single bottom-up pass
- Good match to LR parsing
-
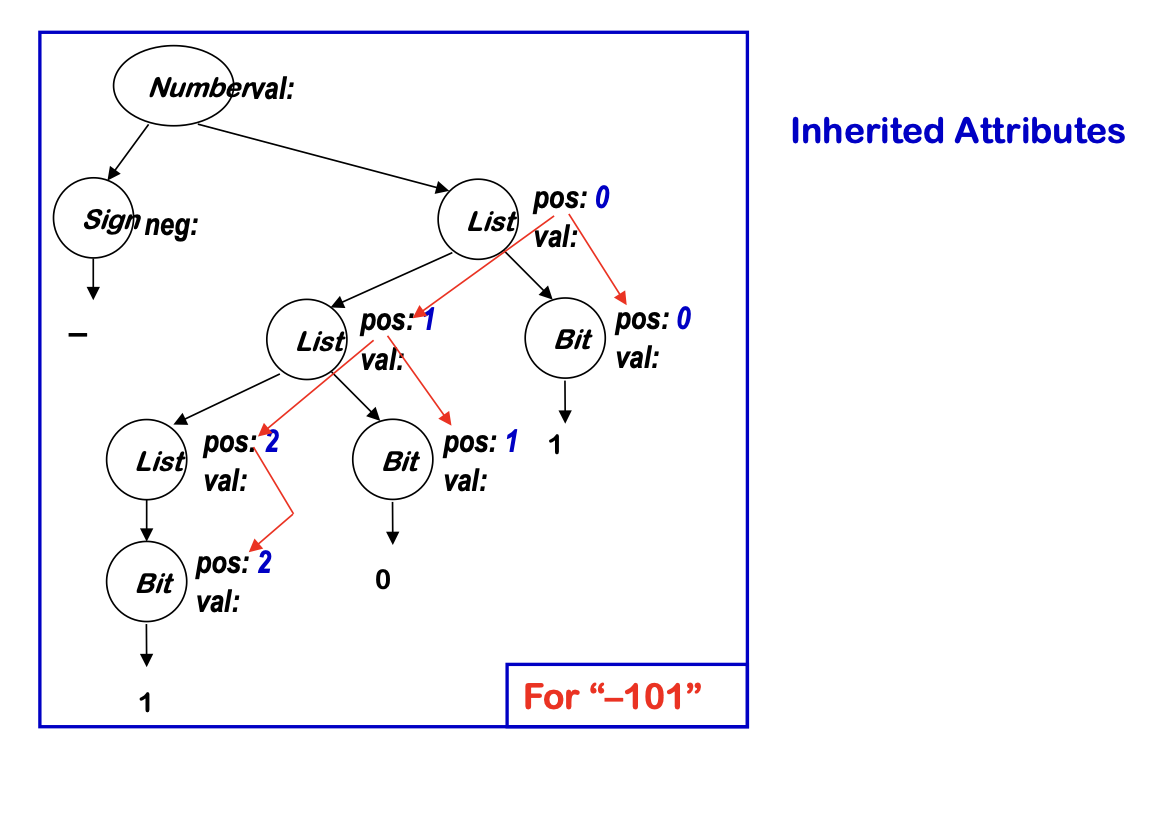
Inherited Attributes
- Use values from parent, constants, & siblings
- L-attributed grammars
- A -> X1X2..Xn and each inherited attribute of Xi depends on
- attributes of X1X2…Xi-1 and inherited attributes of A
- A -> X1X2..Xn and each inherited attribute of Xi depends on
- Evaluate in a single top-down pass (left to right)
- Good match for LL parsing
-
Non local computation needed lots of suppporting rules
-
“Complex” local computation is relatively easy
The problems with AGs
- Copy rules increase cognitive overhead
- Copy rules increase space requirements
- Need copies of attributes
- Result is an attributed tree
- Must build the parse tree
- Either search tree for answers or copy them to the root