
Lecture 8
Bottom-up Allocator
The idea:
- Focus on replacement rather than allocation
- Keep values “used soon” in registers
- Only parts of a live range may be assigned to a physical register (!= top -down allocation’s “all-or-nothing” approach)
Algorithm:
- Start with empty register set
- Load on demand
- When no register is available, free one
Replacement (heuristic): 1
- Spill the value whose next use is farthest in the future
- Sound familiar? Think page replacement
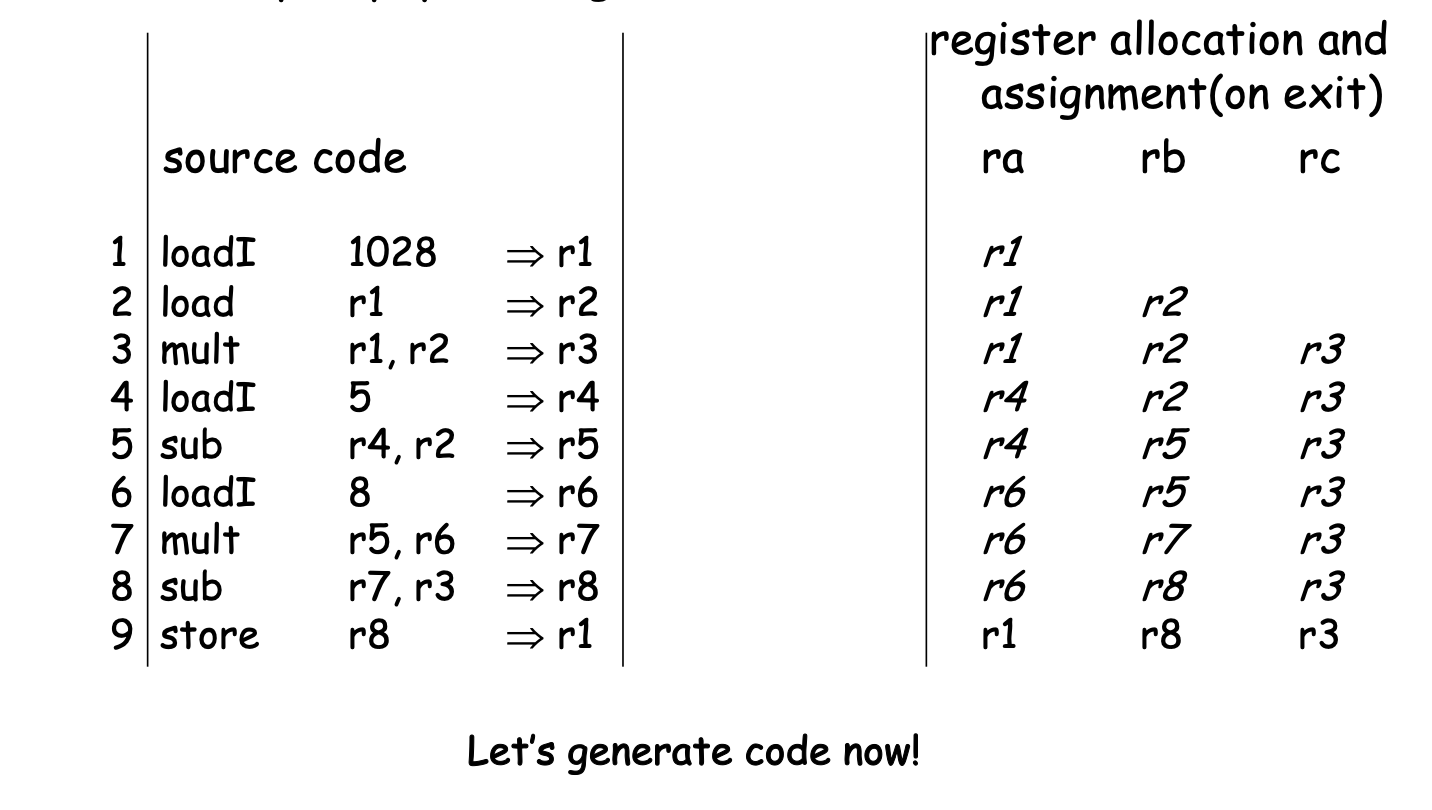
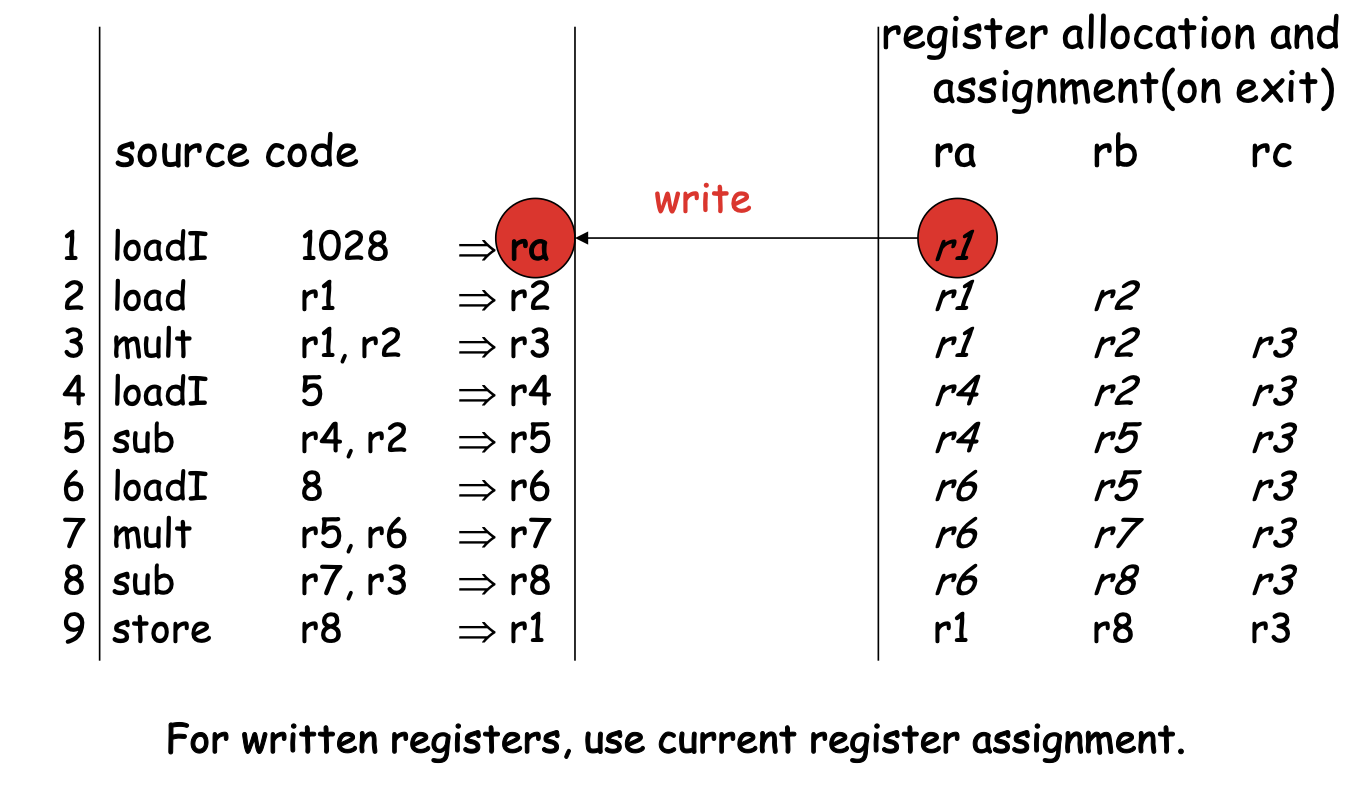
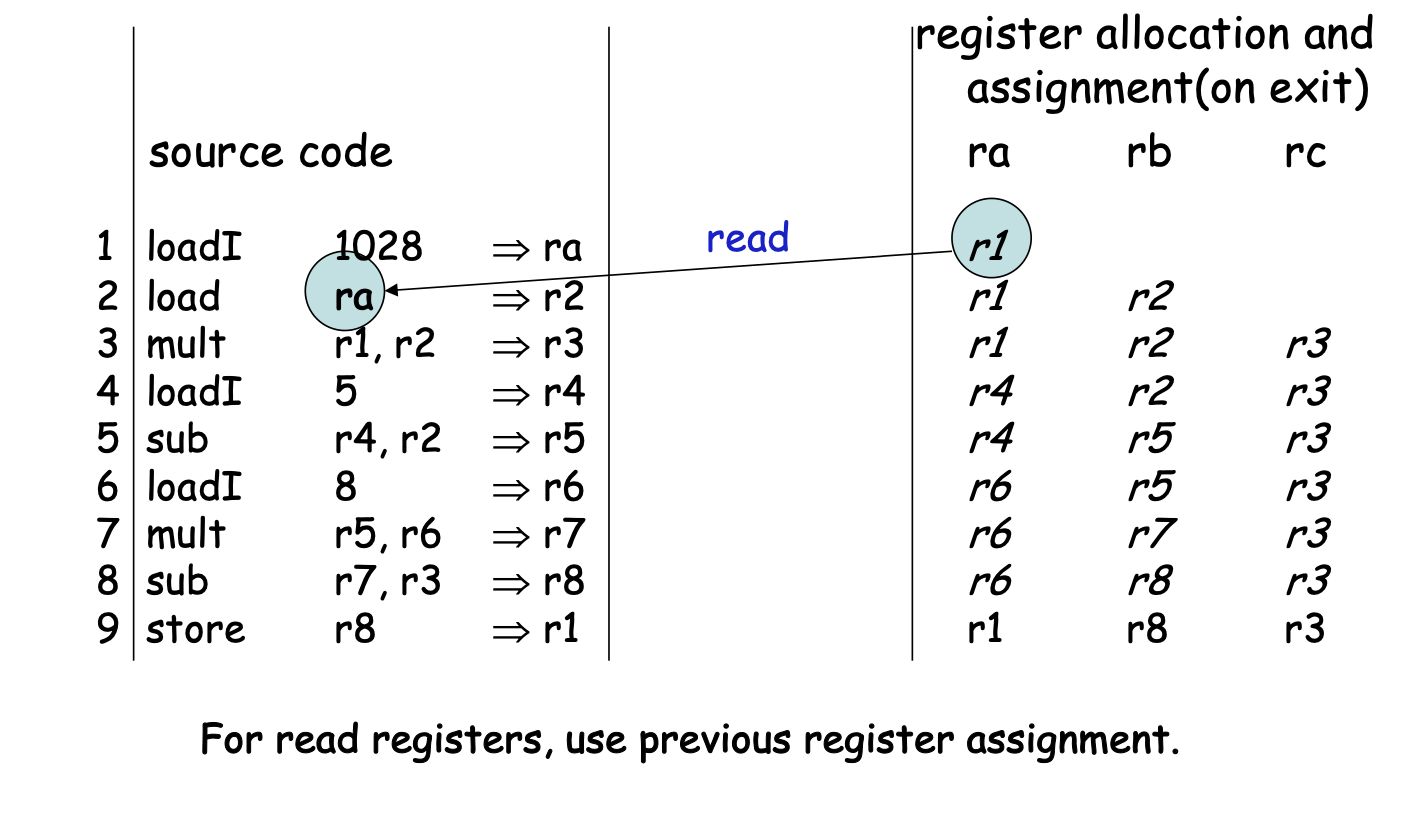
Example:
loadI 1028 => r1 // r1
load r1 => r2 // r1 r2
mult r1,r2 => r3 // r1 r2 r3
loadI 5 => r4 // r1 r2 r3 r4
sub r4,r2 => r5 // r1 r3 r5
loadI 8 => r6 // r1 r3 r5 r6
mult r5,r6 => r7 // r1 r3 r7
sub r7,r3 => r8 // r1 r8
store r8 => r1 //


Spilling revisited
Rematerialization: Re-computation is cheaper than store/load to memory

Bottom-up spilling revisited
Source code example
...
1 add r1,r2 => r3
2 add r4,r5 => r6
...
x need to spill either r3 or r6; both used farthest in the future
...
y add r3,r6 => r27Should r3 or r6 be spilled before instruction x (Assume neither register value can be materialized)
What if r3 has been spilled before instruction x, but r6 has not? Spilling clean register (r3) avoids storing value of dirty register (r6)
The Front End
The purpose of the front end is to deal with the input language
- Perform a membership test: code $\in$ source language?
- Is the program well-formed (semantically)?
- Build an IR version of the code for the rest of the compiler
The front end is not monolithic
Scanner
- Maps stream of characters into words / tokens
- Basic unit of syntax
x = x + y;becomes<id, x><eq, =><id,x><pl,+><id,y><sc,;>
- Character sequence that forms a word/token is its lexeme
- Its part of speech or (syntactic category) is called its token type
- Scanner discards white space & (often) comments
- Speed is often an issue in scanning => use a specialized recognizer
Parser
- Checks stream of classified words (tokens) for grammatical correctness
- Determines if code is syntactically well-formed
- Guides checking at deeper levels than syntax (static semantics)
- Builds an IR representation of the code