Lecture 20 - Code Generation, IRs
Roadmap for the remainder of the course
- Project #2 - Due Friday April 15
- Homework #5 has been posted
- Final exam on May 10th, 1:00 pm
- Grading scheme
- Exams: 2 x 30% (best 2 count)
- Projects: 3 x 10%
- Homework: 5 x 2% (best 5 count)
Code Generation
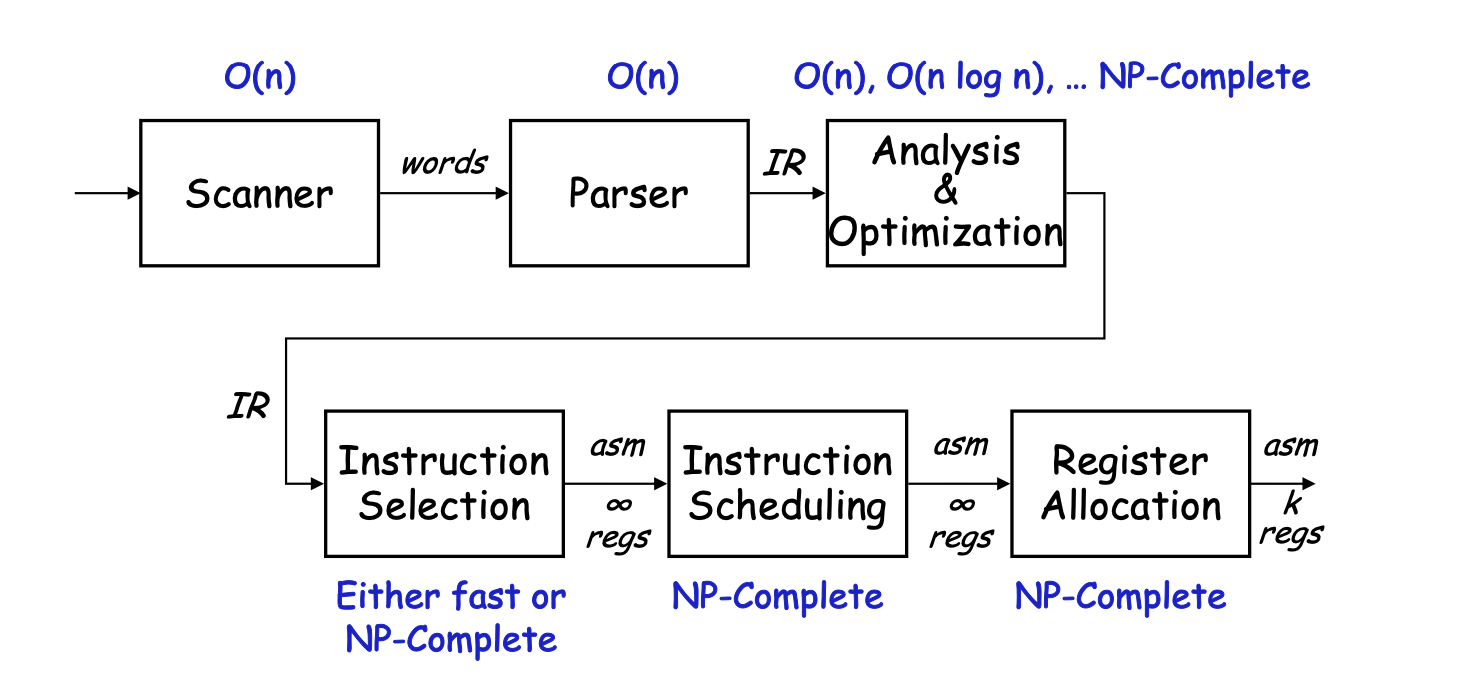
A compiler is a lot of fast stuff followed by some hard problems
- The hard stuff is mostly in code generation and optimization
- For super scalars, its allocation & scheduling that is particularly important
Review - Generating Code
The key code quality issue is holding values in registers
- When can a value be safely allocated to a register?
- When only 1 name can reference its value (no aliasing)
- Pointers, parameters, aggregates & arrays all cause trouble
- When should a value be allocated to a register?
- When its both safe and profitable
Encoding this knowledge into the IR (register-register model)
- Use code shape to make it known to every later phase
- Assign a virtual register to anything that can go in one
- Load or store the others at each reference
Relies on a strong register allocator
Recursive Treewalk vs. ad-hoc SDT

Handling Assignment
lhs <- rhs
Strategy
-
Evaluate rhs to a value
-
Evaluate lhs to a location (memory address)
- lvalue is an address => store rhs
-
If rvalue & lvalue have different types
- Evaluate rvalue to its “natural” type
- Convert that value to the type of lhs value, if possible
-
Unambiguous scalars may go into registers (no aliasing)
-
Ambiguous scalars or aggregates go into memory (possible aliasing)
What if the compiler cannot determine the rhs’s type?
- This is a property of the language & the specific program
- If type safety is desired, compiler must insert a run-time check
- Add a tag field to the data items to hold type information
Code for assignment becomes more complex
evaluate rhs
if lhs.type_tag != rhs.type_tag
then
convert rhs to type(lhs) or signal a run time error
lhs <- rhsCompile time type checking
- The goal is to eliminate both the runtime check & the tag
- Determine, at compile time, the type of each sub expression
- Use compile-time types to determine if a run-time check is needed
Optimization strategy
- If compiler knows the type, move the check to compile time
- Unless tags are needed for garbage collection, eliminate them
- If check is needed, try to overlap it with other computation (superscalar or multi-core architectures)
Reference Counting
The problem with reference counting
- Must adjust the count on each pointer assignment
- Overhead is significant, relative to assignment
Code for assignment becomes
evaluate rhs
lhs->count <- lhs->count - 1
lhs <- addr(rhs)
rhs->count <- rhs->count + 1This adds 1 add, 1 sub, 2 loads and 2 stores
With extra functional units & large caches, this may become either cheap or free. What about power consumption
Arrays
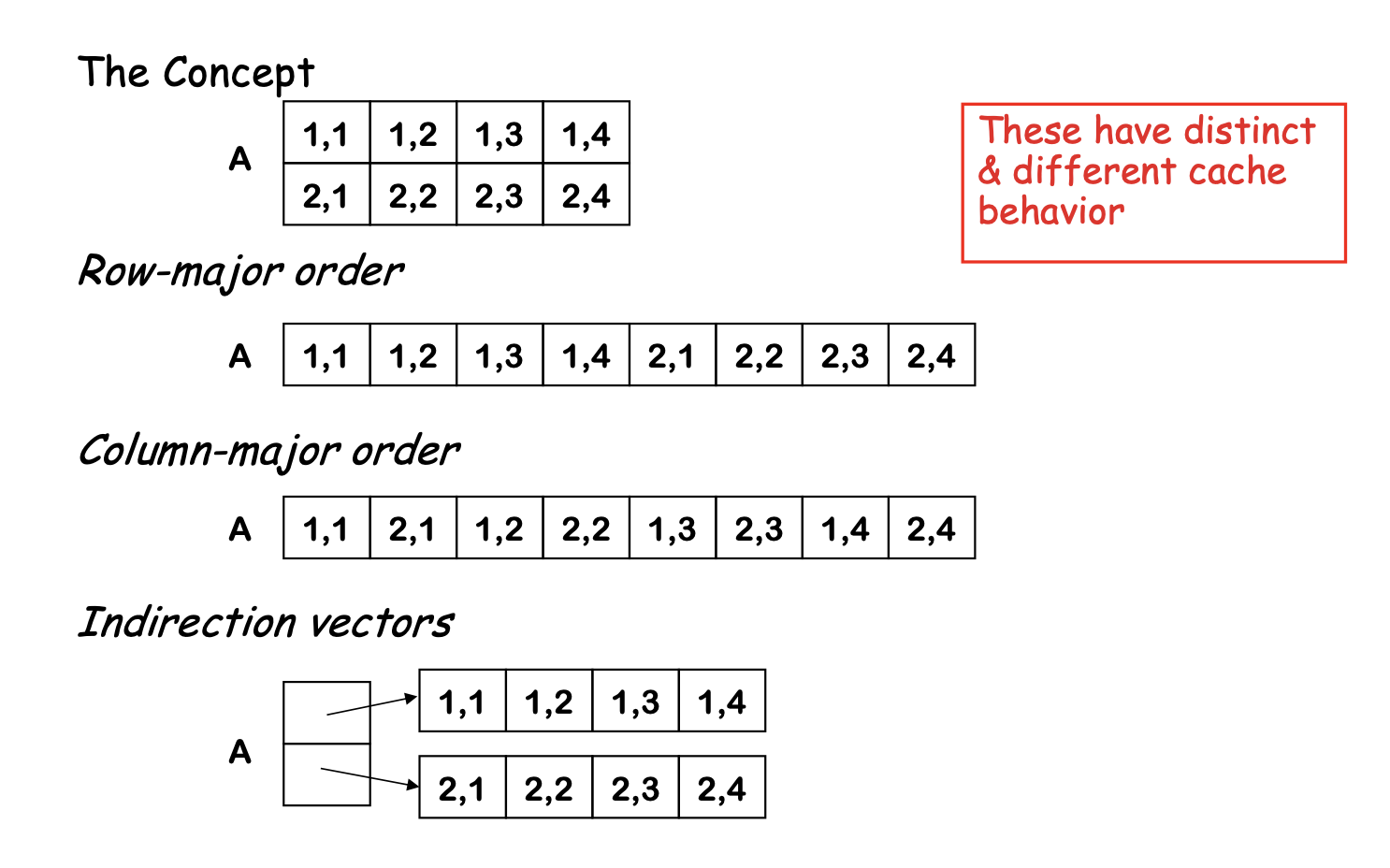
How does the compiler handle A[i,j]?
First, we must agree on a storage scheme
- Row-major order
- Lay out as a sequence of consecutive rows
- Rightmost subscript varies fastest
A[1,1], A[1,2], A[1,3], A[2,1], A[2,2], A[2,3]- Most languages do this
- Column-major order
- Lay out as a sequence of columns
- Leftmost subscript varies fastest
A[1,1], A[2,1], A[1,2], A[2,2], A[1,3], A[2,3]- Fortran does this
- Indirection vectors
- Vector of pointers to pointers to … to values
- Takes much more space, takes indirection for arithmetic
- Not amenable to analysis
Layout
Computing an Array Address
A[i]- In general,
base(A) + (i - low) x sizeof(A[1])
- In general,
A[i1,i2]- Row-major order, two dimensions:
base(a) + ((i1 - low1) x (high2 - low2 + 1) + i2 - low2) x sizeof(A[1])
- Column-major order, two dimensions:
base(a) + ((i2 - low2) x (high1 - low1 + 1) + i1 - low1) x sizeof(A[1])
- Indirection vectors, two dimensions
*(A[i1])[i1]- whereA[i1]is, itself, a 1d array reference
- Row-major order, two dimensions:
Optimizing 2d Array Accesses

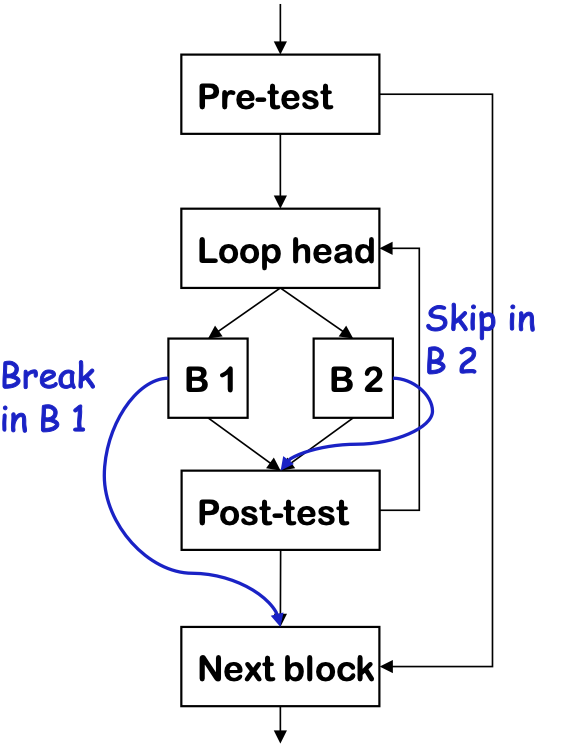
Control Flow
One possible approach for code generation:
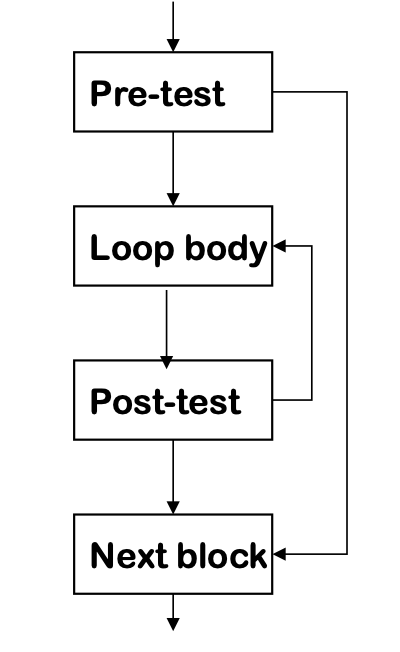
Loops:
-
Evaluate condition before loop (if needed)
-
Evaluate condition after loop
-
Branch back to the top (if needed)
-
Merges test with last block of loop body
-
while,for,do, anduntilall fit this basic model
Loop Implementation Code
for (i = 1; i < 100; i++) { body}
next statementWould get turned into
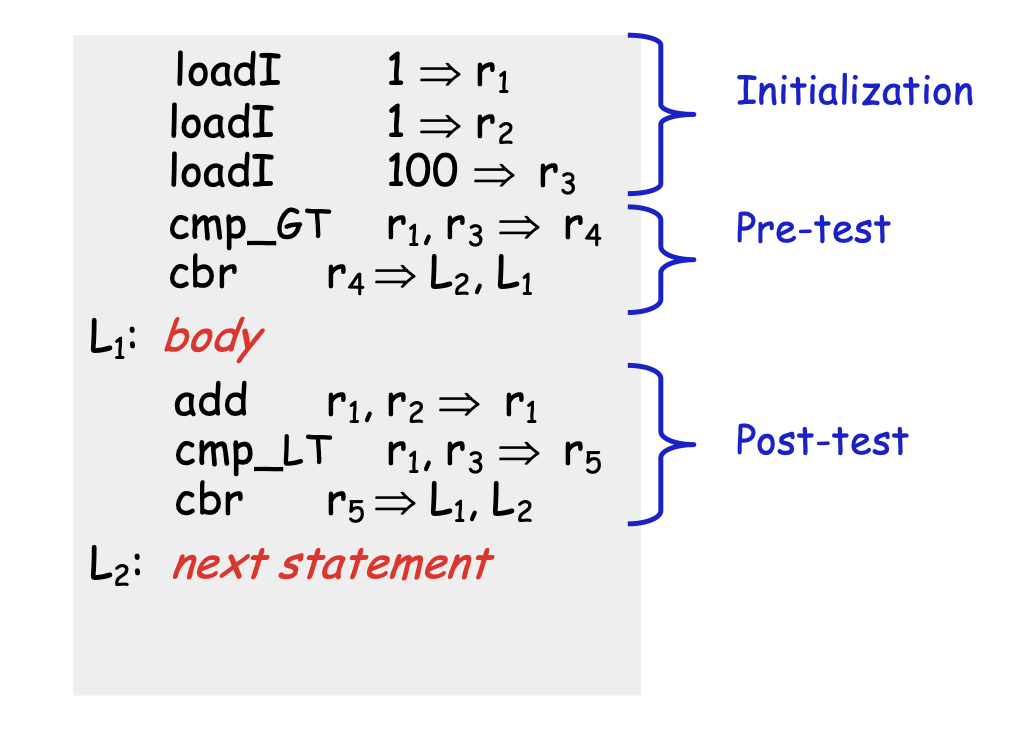
Break statements
Many modern programming languages include a break
- Exits from the innermost control-flow statement
- Out of the innermost loop
- Out of a case statement
- Translates into a jump
- Targets statement outside control-flow construct
- Creates multiple-exit construct
- Skip in loop goes to next iteration